<<<
Chronological Index
>>> <<<
Thread Index
>>>
RE: [ssac-gnso-irdwg] Draft: Questions for ICANN IDN staff - Tina Dam - from the WhoIs IRD WG
- To: "James M Galvin" <jgalvin@xxxxxxxxxxxx>, "Dave Piscitello" <dave.piscitello@xxxxxxxxx>, "Robert C. Hutchinson" <rchutch@xxxxxxxxx>, "Ird" <ssac-gnso-irdwg@xxxxxxxxx>
- Subject: RE: [ssac-gnso-irdwg] Draft: Questions for ICANN IDN staff - Tina Dam - from the WhoIs IRD WG
- From: "Owen Smigelski" <Owen.Smigelski@xxxxxxxxxxxx>
- Date: Tue, 25 Jan 2011 09:55:38 -0800
Someone who works at my office is from Quebec, and his last name has é as the
last character. I just checked, and that does not appear on his California
driver’s license or his US social security card. His paycheck was once
rejected because it contained the accent mark and his bank account did not.
It’s been many years since he applied for his government documents, so he is
not aware if they are prohibited, but he does recall there being issues of the
mixed ASCII characters.
As for Chinese characters, there are two ways of writing Chinese words:
Traditional and Simplified. Both have the same exact meaning, it’s just that
Simplified is… easier (some characters have less strokes). Simplified Chinese
was created by PRC, and is the official script there. It is thus rejected by
Taiwan, where Traditional is the official script. Hong Kong still uses
Traditional, but Simplified is gaining ground since it became part of the PRC.
Other Chinese speaking countries (Malaysia, Singapore) have adopted Simplified,
and Traditional remains used by Chinese speakers in other countries (e.g. US
and Europe). Many Simplified and Traditional characters are the same, and it
is possible to see words that use a Simplified over a Traditional character,
but it would appear odd to a Chinese speaker. When my company files
trademarks, it is either all Traditional or all Simplified characters. As for
a person’s name, which is registered by a government authority, you will not
see mixed Traditional/Simplified.
Until recently Traditional characters were frowned upon in legal filings in PRC
(at least regarding trademarks and patents some characters were banned), but
the two states are working closer together now so they are relaxing these
restrictions (and some Simplified characters are now recognized/used in
Taiwan).
Here’s a good analogy for Simplified/Traditional:
SIMPLIFIED: By the King.
TRADITIONAL:
It would certainly appear odd to see the two different types of characters
mixed, which is why you do not see Simplified/Traditional Chinese mixed (except
where the character is the same in Simplified and Traditional).
Regards,
Owen
CONFIDENTIALITY NOTICE: This message is intended only for the use of the
individual or entity to which it is addressed, and may contain information that
is privileged, confidential, and exempt from disclosure under applicable law.
If you have received this email in error, please immediately notify the sender
by return email and delete this email and any attachments from your system.
-----Original Message-----
From: owner-ssac-gnso-irdwg@xxxxxxxxx [mailto:owner-ssac-gnso-irdwg@xxxxxxxxx]
On Behalf Of James M Galvin
Sent: Tuesday, January 25, 2011 08:47
To: Dave Piscitello; Robert C. Hutchinson; Ird
Subject: Re: [ssac-gnso-irdwg] Draft: Questions for ICANN IDN staff - Tina Dam
- from the WhoIs IRD WG
Excellent questions Dave!
I don't know the answers off hand and I do think the answers would be
useful. Does anyone have any insight into the answers?
Jim
-- On January 25, 2011 4:20:40 AM -0800 Dave Piscitello
<dave.piscitello@xxxxxxxxx> wrote regarding Re: [ssac-gnso-irdwg]
Draft: Questions for ICANN IDN staff - Tina Dam - from the WhoIs IRD WG
--
>
> Hi all,
>
> Again, apologies for missing yesterday's call.
>
> I have a question related to this discussion. In composing language
> tables with "legitimate" characters for a language, I began to wonder
> whether there are real world constraints on mixed scripts in the
> composition of names.
>
> For example, can a US citizen have a birth certificate where the
> given or surname contains letters other than A-Z? I believe a US
> citizen can have a name containing characters from extended ASCII
> sets (umlauts, tildes, etc). People often name their children
> unconventionally: could someone compose a name for my child that
> contained both an umlaut and tilde?) and would this be accepted as a
> legal name in the US (or other country)? Would a "yes" answer to
> these questions influence this discussion?
>
> Can a Chinese citizen have a surname that is composed of characters
> from one accepted Chinese script and a given name composed using
> characters from a second?
>
> Apologies if this is off topic. Feel free to send me away for more
> coffee.
>
> On 1/25/11 4:12 AM, "Robert C. Hutchinson" <rchutch@xxxxxxxxx> wrote:
>
> > Hello WhoIs IRD WG,
> > Here is my suggested questions for discussion between the Whois IRD
> > WG and ICANN IDN Staff / Tina Dam.
> > Reply with your clarifications and suggestions.
> > Thanks,
> > Bob Hutchinson
> >
> >
> > The WhoIs IRD WG is requesting expertise/assistance from the IDN
> > team. The WhoIs IRD WG is considering recommending that WhoIs
> > Internationalized Domain name registrant data [name and address]
> > for owner and contact be tagged with language. Furthermore, it
> > would be advantageous to constrain the content of language tagged
> > fields to only the legitimate characters of the tagged language.
> > Ideally we would like to locate existing UTF-8 language tables and
> > reference them, rather than creating "ICANN WHOIS language tables".
> >
> > Based on reviewing the IDN ccTLD Fast-Track Workshop slides,
> > http://sel.icann.org/node/6740/, the IDN team addressed similar
> > issues surrounding the use of scripts, languages and character sets.
> > Apparently the IDN team decided that each TLD/registry would define
> > the language character sets acceptable for 2nd-level domain names.
> > Those files are stored at IANA:
> > http://www.iana.org/domains/idn-tables/ and reference linked
> > character code pages. This system provides the flexibility for each
> > TLD to define each language, but has the disadvantage [for example]
> > of defining the Swedish character set three different ways.
> >
> > We would like to invite members of the IDN team to discuss the
> > following questions with the Whois IRD WG:
> > 1) Given the current state of IDN language definitions are there
> > ways/suggestions that the existing IANA-IDN language definitions
> > could be leveraged to help with WhoIs IRD?
> > 2) Did the IDN team explore or select a suitable established
> > ³standard² language tags/code? Like ISO 639-3
> > http://en.wikipedia.org/wiki/List_of_ISO_639-1_codes for
> > designating which language a domain name [TLD or second-level] is
> > encoded in? 3) Are there other [ISO{8859/2022}/HTML?] language
> > code page standards which are UTF-8 based, which could be
> > used/leveraged to easily define WhoIs IRD language character sets?
> > 4) Help? Any suggestions are greatly appreciated.
>
>
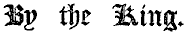
<<<
Chronological Index
>>> <<<
Thread Index
>>>
|